
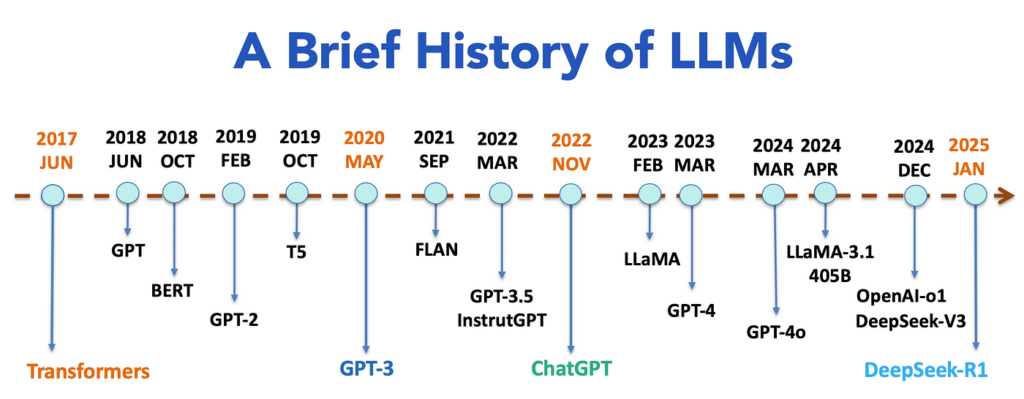
1.时间线
2017年:Transformer的诞生:一切的开端
在Transformer出现之前,主流序列模型是RNN和CNN,但它们有两个致命缺陷:
无法高效处理长文本(例如RNN记不住太长的对话);
训练速度慢(RNN必须逐字处理,无法并行计算)。
Transformer的突破:
Google团队在论文《Attention is All You Need》中提出了一种新架构:
自注意力机制:让模型能同时关注文本中所有位置的关系(例如理解”它”指代的是前文中的”苹果”还是”手机”);
并行计算:大幅提升训练速度(比RNN快10倍以上)。
影响:
Transformer成为大模型的“通用引擎”,为后续所有突破打下基础。
2018年:BERT与GPT分道扬镳——理解与生成的两条路
为什么分化:
研究者发现Transformer可以朝两个方向演进:
BERT(Google):通过“完形填空”训练(掩盖部分文本让模型预测),擅长理解语义(比如搜索、问答);
GPT-1(OpenAI):通过“预测下一个词”训练,擅长生成连贯文本(比如写文章)。
关键点:
BERT是双向的(同时看前后文),GPT是单向的(只能看前文),这决定了它们的应用场景;
两者都证明了“预训练+微调”模式的有效性(先用海量数据预训练通用能力,再针对具体任务微调)。
2019-2020年:暴力美学——越大越好?
核心事件:
GPT-2/GPT-3(OpenAI):参数从15亿(GPT-2)暴涨到1750亿(GPT-3),模型展现“涌现能力”(例如无监督学习、多任务处理)。
T5(Google):提出“万物皆可文本”的统一框架(把翻译、摘要等任务都转化为文本生成问题)。
驱动力:
实验证明模型规模与性能正相关(参数越多,数据量越大,模型越聪明);
云计算(如GPU集群)和投资(OpenAI获微软10亿美元)让“暴力堆参数”成为可能。
2021年:反思与优化——效率 vs 性能
问题暴露:
GPT-3训练一次耗资460万美元,碳排放量相当于一辆汽车绕地球开100圈;
大模型存在偏见、胡说八道(幻觉问题)、难以落地到具体场景。
解决方案:
高效化:如Switch Transformer(Google)用“稀疏激活”技术,用1/7算力达到同等效果;
专业化:如Codex(OpenAI)专注代码生成,证明垂直领域的小模型可能比通用大模型更实用。
2022年:多模态融合——打破文字枷锁
代表模型:
CLIP(OpenAI):连接文本与图像(比如用文字描述生成图片);
DALL-E 2:根据文本生成高质量图片;
PaLM(Google):整合视觉、语言、机器人控制。
为什么重要:
人类通过多感官认知世界,单一文本模型无法满足真实需求(比如医生需要同时看CT影像和病历文本)。
2023年:开源与平民化——技术民主化
关键事件:
LLaMA(Meta):开源130亿参数模型,手机都能跑;
Alpaca/LoRA:用几百美元微调小模型达到接近GPT-3.5的效果。
意义:
打破OpenAI/Google的技术垄断,催生创业潮(如个人开发者也能做AI应用);
引发安全争议(开源模型可能被用于制造假新闻、垃圾邮件)。
2024年:竞争与反思——实用主义的回归
趋势:
价值观对齐:Claude(Anthropic)、GPT-4通过人类反馈强化学习(RLHF)减少有害输出;
小型化:如微软Phi-3用38亿参数实现接近GPT-3.5的能力;
垂直化:法律、医疗、金融等专用模型爆发(例如BloombergGPT)。
底层逻辑:
行业从“盲目追求参数规模”转向平衡能力、成本、安全、能耗,让技术真正落地。
总结:技术发展的核心逻辑
需求驱动:从解决具体问题(如长文本处理)到满足复杂场景(多模态);
硬件与数据的飞轮:GPU算力提升+互联网数据爆炸支撑模型扩张;
商业与开源的博弈:大公司争夺主导权 vs 社区推动平民化;
社会反馈修正方向:安全、伦理、环保问题倒逼技术优化。
未来的核心挑战已从“如何让模型更强大”转向“如何让强大模型安全服务于人”。
2. Transformer
这是测试文本,单击 “编辑” 按钮更改此文本。